
OLAC Overview
| Steven Bird University of Pennsylvania |
Gary Simons SIL International |
|
OLAC Overview
|
Today, language technology and the linguistic sciences are confronted with a vast array of language resources, richly structured, large and diverse. Texts, recordings, dictionaries, annotations, software, protocols, data models, file formats, newsgroups and web indexes are just some of these resources. The resources are growing in size, in number, in diversity.
Today, multiple communities depend on language resources, including linguists, engineers, teachers and actual speakers. Many individuals and institutions provide key pieces of the infrastructure, including archivists, software developers, and publishers. The sponsors and promoters of language technology and the linguistic sciences -- professional associations, government funding agencies, and non-governmental organizations - also need to access and deploy language resources. These communities are large. For example, the LinguistList network counts over 13,000 members. The Linguistic Data Consortium produces linguistic databases for some 1,000 organizations. The number of individuals having an immediate interest in language resources numbers in the tens of thousands. These communities are growing in size, in number, in diversity.
And today, we have unprecedented opportunities to connect these communities to the language resources they need. First, inexpensive mass storage technology permits large resources to be stored in digital form, while the Extensible Markup Language (XML) and Unicode provide flexible ways to represent structured data and ensure its long-term survival. Second, digital publication - both on and off the world wide web - is the most practical and efficient means of sharing language resources. Finally, a standard resource classification model, the Dublin Core Metadata Set, together with an interchange method provided by the Open Archives Initiative, make it possible to construct a union catalog over multiple repositories and archives. This infrastructure is a new invention; it has the bottom-up, distributed character of the web, while simultaneously having the efficient, structured nature of a centralized database. This combination is well-suited to the language resource community, where the available data is growing rapidly and where a large user-base is consistent in how it describes its resource needs.
In December 2000, an NSF-sponsored workshop on Web-Based Language Documentation and Description brought together a a group of nearly 100 language software developers, linguists, and archivists who are responsible for creating language resources in North America, South America, Europe, Africa, the Middle East, Asia and Australia. Over four days of presentations, panel sessions, and working groups, the participants explored the opportunities listed above. The outcome of the workshop was the founding of the Open Language Archives Community (OLAC), an application of the Open Archives Initiative to digital archives of language resources. An advisory board was established and alpha-testers identified. This project will provide technical infrastructure for the Open Language Archives Community.
Before presenting the technical background to the project, it would be instructive to give a hypothetical example to illustrate what the Open Language Archives Community will be like. Suppose that a user goes to an OLAC ``service provider'' website, which presents a form that permits focused searching on OLAC metadata fields.
In this imaginary interaction, a user is searching for data from a Quechua language. The system discovers that ``Quechua'' actually denotes 59 different languages, and the user is taken to a controlled vocabulary server which permits the identifier for the language or interest, in this case Huánuco Quechua, to be entered. Search continues and the resulting display - which looks like the summary of hits produced by a web search engine - lists field notes, a dictionary and a grammar. From this page, the user navigates to the full metadata record for the dictionary, shown in Figure 1.
| |||||||||||||||||||||||||||||||||||||||
| Figure 1: An example metadata record for a Huánuco Dictionary |
The record consists of a list of optional, repeatable metadata elements. Some elements can only take a restricted range of values, so called controlled vocabularies. For example, Subject.language has values defined by RFC 1766. Format.markup will have values defined by OLAC, consisting of a namespace and a name.
The imaginary user continues the exploration, now wanting to find out if there are any tools which understand the format sil-sf. The query is launched by clicking on the TOOLS hyperlink for the Format.markup field. The result is a summary listing of tools, including Shoebox, HyperLex, EUDICO and CLAN, which are archived in four different repositories. The user pulls up the full metadata record for Shoebox, and sees a display much like the one above, but including Rights.openness for the level of availability of the software, Relation.requires for the documentation, and Identifier for the external URL to the software. Some additional fields specifically for software are Type.os for the supported operating systems and Type.functionality for the functions this software can perform.
Finally, the user seeks advice on the appropriateness of this software for the task at hand, and clicks on an ADVICE hyperlink. Some 150 hits are displayed, with such titles as: ``Analyzing data with Shoebox,'' ``Identifying the primary audience dictionary,'' ``Data-entry templates in Shoebox,'' ``Organizing a dictionary by roots vs lexemes.'' As before, the user navigates to a full metadata record for a particular choice, and this provides the entry point to the resource.
Standing back from this particular interaction, we can observe that the individuals who use and create language resources are looking for three things: data, tools, and advice. Figure 2 diagrams this situation.
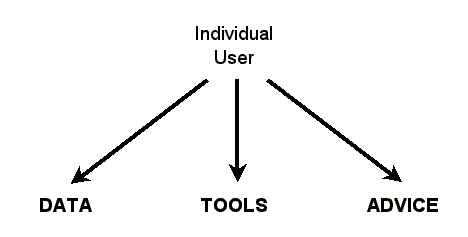
|
| Figure 2: Ideally the user has access as needed |
By DATA we mean any information that documents or describes a language, such as a published monograph, a computer data file, or even a shoebox full of hand-written index cards. The information could range in content from unanalyzed sound recordings to fully transcribed and annotated texts to a complete descriptive grammar. By TOOLS we mean computational resources that facilitate creating, viewing, querying, or otherwise using language data. Tools include not just software programs, but also the digital resources that the programs depend on, such as fonts, stylesheets, and document type definitions. By ADVICE we mean any information about what data sources are reliable, what tools are appropriate in a given situation, what practices to follow when creating new data, and so forth.
Unfortunately, today's user does not have ready access to the data, tools, and advice that are needed. Figure 3 offers a diagrammatic view of the reality. Some archives (e.g. Archive 1) do have a site on the Internet which the user is able to find, so the resources of that archive are accessible. Other archives (e.g. Archive 2) are on the Internet, so the user could access them in theory, but the user has no idea they exist so they are not accessible in practice. Still other archives (e.g. Archive 3) are not even on the Internet. And there are potentially hundreds of archives (e.g. Archive n) that the user needs to know about. Tools and advice are out there as well, but are at many different sites.
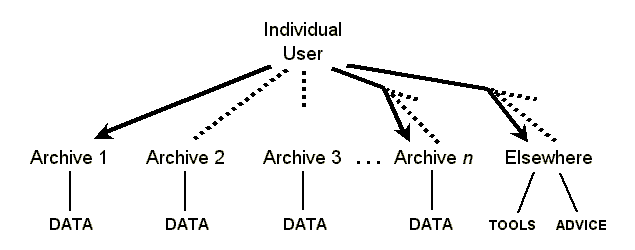
|
| Figure 3: In reality the user can't always get there from here |
There are many other problems inherent in the current situation. For instance, the user may not be able to find all the existing data about the language of interest because different sites have called it by different names. The user may not be able to use an accessible data file for lack of being able to match it with the right tools. The user may locate advice that seems relevant but have no basis for judging its merits.
In order to bridge the gap, the individuals who use and create language documentation and description need a community that provides four things: a gateway, metadata, reviews, and standards:
Figure 4 gives a diagram showing the ``Seven Pillars of Open Language Archiving'' and how they relate. In a graphical form it summarizes how a community would function to bridge the gap between the individual user and all the data, tools, and advice that are out there on the Internet. Note that STANDARDS here concern the computational infrastructure of the community. Particular formats for linguistic content (such as the TEI), would be considered tools with associated advice, and fall outside of the scope of the standards we are talking about here.
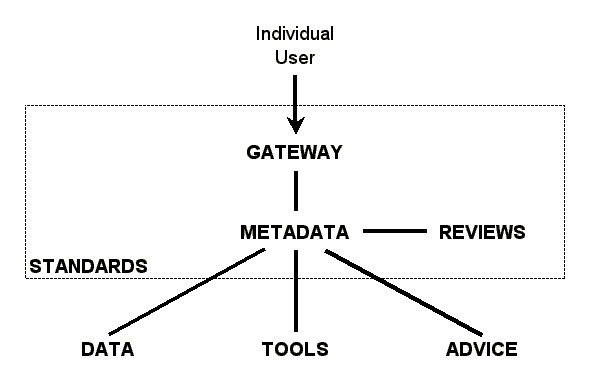
|
| Figure 4: Bridging the gap through community infrastructure |
DATA. As explained in section 2, DATA refers to any information that documents or describes a language, such as a published monograph, a computer data file, or even a shoebox full of hand-written index cards. The information could range in content from unanalyzed sound recordings to fully transcribed and annotated texts to a complete descriptive grammar. Although much language data is never published, it is often archived so that future scholars can access the work. Unfortunately, there is no international register of language archives, and no way to discover what most archives hold except by visiting them in person.
Recently, in an attempt to document these language archives, Bird, Simons and Liberman conducted a survey. The survey and preliminary results are available online [http://www.ldc.upenn.edu/exploration/survey/], as are prose descriptions of each archive [http://www.ldc.upenn.edu/exploration/archives.html]. Most of the surveyed archives have a partial digital catalog, and about 25% have a complete digital catalog. A couple of them use MARC or TEI. We also found that a wide variety of catalog fields are used (or proposed) by these archives, and that no two archives use the same set of fields. The following list contains fields used by at least one of the archives. It gives a glimpse of the kinds of materials which are held, and also illustrates the need for consistency.
TOOLS. By TOOLS we mean computational resources that facilitate creating, viewing, querying, or otherwise using language data. Tools include not just software programs, but also the digital resources that the programs depend on, such as fonts, stylesheets, and document type definitions. Over the past decade, researchers in human language technology have created a vast array of tools, many of which are made openly available. The Association for Computational Linguistics together with the German Research Center for Artificial Intelligence has created the ``Natural Language Software Registry'' [http://registry.dfki.de/]. This is a database that describes 130 language software tools. Its metadata includes license type, functionality, operating system, and the language(s) the tool works with. Interest in this repository has been stimulated recently by a workshop at last year's meeting of the ACL [http://elsnet.let.uu.nl/acl2000workshop.html]. A follow-up workshop will be held at the 2001 meeting.
ADVICE. Many internet mailing lists are concerned with language resources. Chief among them is the Corpora mailing list [http://www.hit.uib.no/corpora/]. Apart from conference and job announcements, the majority of postings on this mailing list are queries about the existence of a certain kind of resource, requests for advice about the suitability of resources for particular tasks, and summaries of the pointers and suggestions that were communicated directly to the person who posted the original request. A centralized version of the same process is exemplified by the LTG Helpdesk [http://www.ltg.ed.ac.uk/helpdesk/]. Links pages which contain commentary about the resources they reference also constitute a kind of advice. For example, the Linguistic Exploration Page [http://www.ldc.upenn.edu/exploration/] surveys and classifies some 60 resources available on the web.
People needing advice typically resort to posting a query on one or more lists, sorting through the responses, and possibly posting a summary of responses back to the lists. However, it is often difficult to decide a good course of action, when the primary information is an uncoordinated set of suggestions originating from strangers on a mailing list. In a period of rapidly evolving technology, a wrong choice can wind up in a dead end, and painstakingly collected data ends up being unusable. Numerous experiences of this community attest to this reality.
The size and complexity of language resources, of data, tools, and advice, is growing rapidly, and yet the way we locate these resources is completely haphazard. While the World-Wide Web holds the promise of unprecedented access to language resources, we also see the specter of frustration and chaos on an unprecedented scale. Coordination is urgently needed, before individual projects develop more needlessly incompatible standards, protocols, interfaces and methods.
The community appears to be arranged into three main groups. The first group is engaged in the core activity of generating and using language resources. The second group provides the technical foundation for this core activity, while the third group constitutes the administrative umbrella. For full details, see Figure 5.
| ||||||||||||||
| Figure 5: The Language Resources Community |
The community is diverse, but is united by its common interest in creating, accessing and/or deploying language resources. However, when it comes to finding relevant resources, people are regularly reduced to sifting through the results returned by web search engines, then further sifting through free-form prose descriptions of holdings. Only by using agreed metadata can these communities be connected with the resources they need.
As the internet grows and web-indexing technologies improve one might hope that a general-purpose search engine should be sufficient to bridge the gap between people and the resources they need, but this is a vain hope. The first reason is that many language resources, such as audio files and software, are not text-based. The second reason concerns language identification, the single most important classification for language resources. If a language has a canonical name which is distinctive as a character string, then the user has a chance of finding any online resources with a search engine. However, the language may have multiple names, possibly due to the vagaries of Romanization, such as a language known variously as Fadicca, Fadicha, Fedija, Fadija, Fiadidja, Fiyadikkya, and Fedicca. The language name may collide with a word which has other interpretations that are vastly more frequent, e.g. the language names Mango and Santa Cruz.
The third reason why general-purpose search engines are inadequate is the simple fact that much of the material is not, and will not, be documented in free prose on the web. The cataloging work will be done either systematically or not at all. Of course, one can always export a back-end database as HTML and let the search engines index the materials. Indeed, encouraging people to document resources and make them accessible to search engines is part of our vision. However, despite the power of web search engines, there remain many instances where people still prefer to use more formal databases to house their data.
This last point bears further consideration. The challenge is to build a system for ``bringing like things together and differentiating among them'' [Svenonius00]. There are two dominant storage and indexing paradigms, one exemplified by traditional databases and one exemplified by the web. In the case of language resources, the metadata is coherent enough to be stored in a formal database, but sufficiently distributed and dynamic that it is impractical to maintain it centrally. Language resources occupy the middle ground between the two paradigms, neither of which will serve adequately. A new framework is required that permits the best of both worlds, namely bottom-up, distributed initiatives, along with consistent, centralized finding aids. The Dublin Core and the Open Archives Initiative provide the framework we need.
The Dublin Core Metadata Initiative began in 1995 to develop conventions for resource discovery on the web [http://purl.org/DC/]. The Dublin Core metadata elements represent a broad, interdisciplinary consensus about the core set of elements that are likely to be widely useful to support resource discovery. The Dublin Core consists of 15 metadata elements, where each element is optional and repeatable: Title, Creator, Subject, Description, Publisher, Contributor, Date, Type, Format, Identifier, Source, Language, Relation, Coverage, Rights. This metadata set can be used to describe resources that exist in digital or traditional formats.
In ``Dublin Core Qualifiers'' two kinds of qualifications are allowed: encoding schemes and refinements [http://purl.org/dc/documents/rec/dcmes-qualifiers-20000711.htm]. An encoding scheme specifies a particular controlled vocabulary or notation for expressing the value of an element. The encoding scheme serves to aid a client system in interpreting the exact meaning of the element content. A refinement makes the meaning of the element more specific. For example, a Subject element can be given a language refinement to restrict its interpretation to concern the ``subject language'' of the resource. A Language element can be encoded using the conventions of RFC 1766 to unambiguously identify the language is written (or spoken).
The Open Archives initiative (OAI) was launched in October 1999 to provide a common framework across electronic preprint archives [http://www.openarchives.org], and it has since been broadened to include digital repositories of scholarly materials regardless of their type.
In the OAI infrastructure, each participating archive implements a repository, a network accessible server offering public access to archive holdings. The primary object in an OAI-conformant repository is called an item, having a unique identifier and being associated with one or more metadata records. Each metadata record describes an archive holding, which is any kind of primary resource such as a document, data, software, a recording, a physical artifact, a digital surrogate, and so forth. Each metadata record will usually contain a reference to an entry point for the holding, such as a URL or a physical location, as shown in Figure 6.
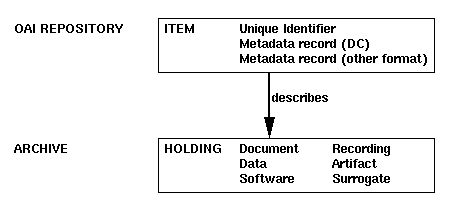
|
| Figure 6: The Relationship Between an OAI Repository and an Archive |
To implement the OAI infrastructure, a participating archive must comply with two standards: the OAI shared metadata set (Dublin Core), which facilitates interoperability across all communities participating in the OAI, and the OAI metadata harvesting protocol, which allows software services to query a repository using HTTP requests.
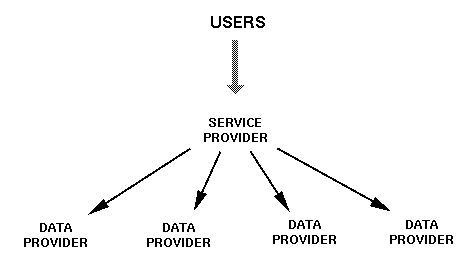
OAI archives are called ``data providers,'' though they are strictly just metadata providers. Typically, data providers will also have a submission procedure, together with a long-term storage system, and a mechanism permitting users to obtain materials from the archive. An OAI ``service provider'' is a third party that provides end-user services (such as search functions over union catalogs) based on metadata harvested from one or more OAI data providers. Figure 7 illustrates a single service provider accessing three data providers. End-users only interact with service providers.
|
| Figure 7: A Service Provider Accessing Multiple Data Providers |
The OAI infrastructure is a new invention; it has the bottom-up, distributed character of the web, while simultaneously having the efficient, structured nature of a centralized database. This combination is well-suited to the language resource community, where the available data is growing rapidly and where a large user-base is fairly consistent in how it describes its resource needs.
In December 2000, an NSF-sponsored workshop on Web-Based Language Documentation and Description brought together a group of some 100 linguists, archivists, software developers, publishers and funding agencies, who are responsible for creating language resources in North America, South America, Europe, Africa, the Middle East, Asia and Australia. The outcome of the workshop was the founding of the Open Language Archives Community (OLAC), which extends the Open Archives Initiative to archives of language resources. An advisory board was established and alpha-testers identified. This section reports on the workshop and its primary outcome.
In December 2000, the University of Pennsylvania hosted a four-day workshop involving language resource experts from all over the world, organized by Steven Bird and Gary Simons [http://www.ldc.upenn.edu/exploration/expl2000/]. The goal of the workshop was as follows:
This workshop will lay the foundation of an open, web-based infrastructure for collecting, storing and disseminating the primary materials which document and describe human languages, including wordlists, lexicons, annotated signals, interlinear texts, paradigms, field notes, and linguistic descriptions, as well as the metadata which indexes and classifies these materials. The infrastructure will support the modeling, creation, archiving and access of these materials, using centralized repositories of metadata, data, best practice guidelines, and open software tools.
Albert Bickford (SIL), described the shared concerns which united the extremely diverse group of participants as follows:
The workshop itself consisted of about 40 presentations, 3 panel sessions, and several working group sessions (all materials, including the program, papers, presentation materials and biographical information about the participants are available online from the above URL). The presentations covered various aspects of the OLAC model, the Open Archives Initiative, metadata for describing language resources, the concerns of various stake-holders, descriptions of projects and demonstrations of systems. The starting point for working group sessions was a requirements document, a comprehensive and compact statement of the needs that unite the various communities.
The primary outcome of the workshop was the founding of the Open Language Archives Community, and with it the identification of an advisory board, alpha testers and member archives. Details of these groups are available from the OLAC Gateway [http://www.language-archives.org].
Recall that the OAI Community is defined by the archives which comply with the OAI Metadata Harvesting Protocol and that register with the OAI. Any compliant repository can register as an Open Archive, and the metadata provided by an Open Archive is open to the public. Now, OAI data providers may support metadata standards in addition to the Dublin Core. Thus, a specialist community can define a metadata format which is specific to its domain. Service providers, data providers and users that employ this specialized metadata format constitute an OAI \emph{subcommunity}. The workshop participants agreed unanimously that the OAI provides a significant piece of the infrastructure needed for the language resources community.
In the same way that OLAC represents a specialized subcommunity with respect to the entire Open Archives community, there are specialized subcommunities within the scope of OLAC. For instance, the ISLE Meta Data Initiative is developing a detailed metadata scheme for corpora of recorded speech events and their associated descriptions \cite{IMDI00}. For archived language resources that of this kind, such a metadata scheme would give much richer description. This specialized subcommunity can implement its own service provider that offers focused searching based on its own rich metadata set.
The LDC Prototype. The Linguistic Data Consortium has harvested the catalogs of three language resource archives (LDC, ELRA, DFKI) and created a demonstration prototype, available online. A search for `language=Bulgarian' returns records from all three archives, as shown in Figure 8.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Figure 8: Querying the Prototype Service Provider for Bulgarian Resources | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||